本文共 7581 字,大约阅读时间需要 25 分钟。
什么是序列化和反序列化
序列化:指堆内存中的java对象数据,通过某种方式把对存储到磁盘文件中,或者传递给其他网络节点(网络传输)。这个过程称为序列化,通常是指将数据结构或对象转化成二进制的过程。
简单来讲:将对象转化为二进制,用于保存,或者网络传输。 反序列化:序列化的逆过程,把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。也就是将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。 简单来讲:将二进制数据转化为对象
为什么需要序列化和反序列化?
现在开发过程中经常遇到多个进程多个服务间需要交互,或者不同语言的服务之间需要交互,这个时候,我们一般选择使用固定的协议,将数据传输过去,但是在很多语言,比如java等jvm语言中,传输的数据是特有的类对象,而类对象仅仅在当前jvm是有效的,传递给别的jvm或者传递给别的语言的时候,是无法直接识别类对象的,那么,我们需要多个服务之间交互或者不同语言交互,该怎么办?这个时候我们就需要通过固定的协议,传输固定的数据格式,而这个数据传输的协议称之为序列化,而定义了传输数据行为的框架组件也称之为序列化组件(框架)。
以下从网络通信角度来分析: 现在我们网络通信一般是基于TCP/IP协议进行,假设两台电脑,一个电脑上有java源程序,另一个电脑需要使用该程序服务,两个进程进行通信时候,想要发送数据,要先要把数据发送到TCP缓冲区,然后形成报文再发送出去,同样的道理,接收端也是一样。我们可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。同样的,当两个Java进程进行通信时,也可以使用序列化技术实现对象之间的传递。所以实现不同终端的通信是需要序列化和反序列化机制的。
序列化的作用
1 永久性保存对象,保存对象的字节序列到本地文件或者数据库中
2 通过序列化以字节流的形式使对象在网络中进行传递和接收 3 通过序列化在进程间传递对象
序列化的优点
1 实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上
2 利用序列化实现远程通信,即在网络上传送对象的字节序列
序列化的实现
Java中序列化的实现很多种,这里主要针对经典的实现Serializable接口的方式进行举例学习,不同的序列化方式使用场景不一样。实现Serializable接口是一种最直接的方式。
1 创建User类(注意实现Serializable接口)我这里用的 jdk 11 不用序列化ID了,貌似有些版本需要定义 序列化ID
在类中定义这样一句话: private static final long serialVersionUID = 1L;这个序列化ID起着关键的作用,它决定着是否能够成功反序列化!java的序列化机制是通过判断运行时类的serialVersionUID来验证版本一致性的,在进行反序列化时,JVM会把传进来的字节流中的serialVersionUID与本地实体类中的serialVersionUID进行比较,如果相同则认为是一致的,便可以进行反序列化,否则就会报序列化版本不一致的异常。
即序列化ID是为了保证成功进行反序列化 当我们一个实体类中没有显式的定义一个名为“serialVersionUID”、类型为long的变量时,Java序列化机制会根据编译时的class自动生成一个serialVersionUID作为序列化版本比较,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID。譬如,当我们编写一个类时,随着时间的推移,我们因为需求改动,需要在本地类中添加其他的字段,这个时候再反序列化时便会出现serialVersionUID不一致,导致反序列化失败。那么如何解决呢?便是在本地类中添加一个“serialVersionUID”变量,值保持不变,便可以进行序列化和反序列化。 如果没有显示指定serialVersionUID,会自动生成一个。 只有同一次编译生成的class才会生成相同的serialVersionUID 但是如果出现需求变动,Bean类发生改变,则会导致反序列化失败。为了不出现这类的问题,所以我们最好还是显式的指定一个serialVersionUID。
import java.io.Serializable;public class User implements Serializable { private Integer id; private String name; private Integer age; private byte sex; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public byte getSex() { return sex; } public void setSex(byte sex) { this.sex = sex; } @Override public String toString() { return "User{" + "id=" + id + ", name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}'; }} 2 写发送端
import java.io.IOException;import java.io.ObjectInputStream;import java.net.ServerSocket;import java.net.Socket;public class InputMain { public static void main(String[] args) throws IOException, ClassNotFoundException { ServerSocket s=new ServerSocket(8080); Socket soc=s.accept(); try(ObjectInputStream ois=new ObjectInputStream(soc.getInputStream())){ User u=(User)ois.readObject(); //EUser u=(EUser)ois.readObject(); System.out.println("==========="+u.toString()); }catch(Exception e){ e.printStackTrace(); System.err.println("==wrong info=="); }finally{ if(soc.isClosed()){ soc.close(); } if(s.isClosed()){ s.close(); } } }} 3 写接收端
import java.io.IOException;import java.io.ObjectOutputStream;import java.net.Socket;public class OutMain { public static void main(String[] args) throws IOException { Socket s=new Socket("localhost",8080); try(ObjectOutputStream oos=new ObjectOutputStream(s.getOutputStream())){ User u=new User(); //EUser u=new EUser(); u.setAge(12); u.setName("abc"); u.setId(1); u.setSex((byte)0); oos.writeObject(u); oos.flush(); System.out.println("--->对象已发送:"+u.toString()); }catch(Exception e){ e.printStackTrace(); System.err.println("对象发送失败..."); }finally{ if(!s.isClosed()){ s.close(); } } }} 4 这里运行测试时,注意先运行接收端InputMain类,也就是接收端先打开,然后运行发送端OutMain,最后有以下运行结果:
打开InputMain控制台等待接收:
 发送端OutMain打开
发送端OutMain打开 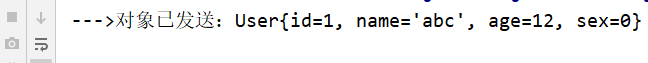 接收端会看到:
接收端会看到: 
以上就是常规的序列化和反序列化的实验了,这里我们要注意,有时候针对某个属性我们可能不需要序列化,如何选择性的序列化呢?有两种途径:
1 实现 Serializable 接口 和 使用 transient 关键字 2 实现 Externalizable 接口,重写其中的writeExternal和readExternal这个接口其实是Serializable的一个子类:
1 将User类中的 id 使用 transient 修饰:
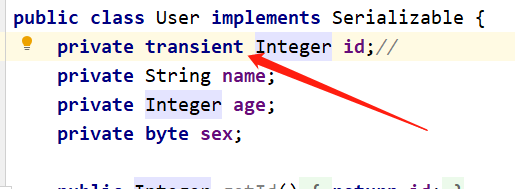 运行以上的 InputMain 和 OutMain 进行测试,可以看到:
运行以上的 InputMain 和 OutMain 进行测试,可以看到:  接收端 id 没有接收了:
接收端 id 没有接收了: 
2 将 类 实现 Externalizable 接口,注意重写的方法
import java.io.Externalizable;import java.io.IOException;import java.io.ObjectInput;import java.io.ObjectOutput;public class EUser implements Externalizable{ private Integer id; private transient Integer age; private String name; private byte sex; public EUser(){ } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public byte getSex() { return sex; } public void setSex(byte sex) { this.sex = sex; } @Override public String toString() { return "EUser{" + "id=" + id + ", age=" + age + ", name='" + name + '\'' + ", sex=" + sex + '}'; } @Override public void writeExternal(ObjectOutput objectOutput) throws IOException { objectOutput.writeObject(this.name); objectOutput.writeByte(this.sex); objectOutput.writeInt(this.age); } @Override public void readExternal(ObjectInput objectInput) throws IOException, ClassNotFoundException { //按照序列化的顺序获取反序列化的字段 this.name = objectInput.readObject().toString(); this.sex = objectInput.readByte(); this.age = objectInput.readInt(); }} 然后测试以上的 InputMain 和 OutMain方法,看到即使age用了transient修饰,但是只要在 重写的方法里序列化了 age 则仍会有有 age的出现,但是 id 没有序列化,所以id 会是null .

 这也说明了 Externalizable 接口可以自定义序列化的属性,这个可以方便我们的开发。
这也说明了 Externalizable 接口可以自定义序列化的属性,这个可以方便我们的开发。 序列化和反序列化的应用:深度拷贝(对象克隆)
这个应该大家都知道:深拷贝和浅拷贝的区别:
浅拷贝:使用一个已知实例对新创建实例的成员变量逐个赋值,这个方式被称为浅拷贝。 深拷贝:当一个类的拷贝构造方法,不仅要复制对象的所有非引用成员变量值,还要为引用类型的成员变量创建新的实例,并且初始化为形式参数实例值。这个方式称为深拷贝。
深度拷贝代码
import java.io.*;public class CloneUtils { public static T clone(T obj) throws Exception { T cloneObj=null; ByteArrayOutputStream bos=new ByteArrayOutputStream(); ObjectOutputStream oos=new ObjectOutputStream(bos); oos.writeObject(obj); oos.flush(); ByteArrayInputStream bis=new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois=new ObjectInputStream(bis); return (T)ois.readObject(); }} 测试:

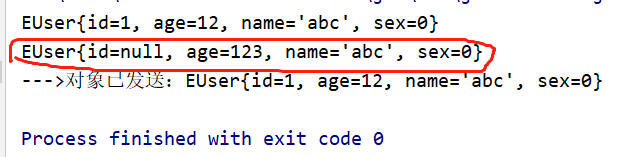 这里注意一个问题:深度拷贝时,如果原对象中存在不可序列化的属性,则序列化实现的深度拷贝也是拷贝不出来的,比如 id 属性为 null 但深度拷贝后的对象是可以自己重新定义属性的 比如 age 属性
这里注意一个问题:深度拷贝时,如果原对象中存在不可序列化的属性,则序列化实现的深度拷贝也是拷贝不出来的,比如 id 属性为 null 但深度拷贝后的对象是可以自己重新定义属性的 比如 age 属性 Java序列化使用的总结
序列化使用的一些经验总结:
1 Java 序列化只是针对对象的属性的传递,至于方法、静态变量和序列化过程无关2 当一个父类实现了序列化,那么子类会自动实现序列化,不需要显式实现序列化接口,如果想写,也可以,反过来,子类实现序列化,而父类没有实现序列化则序列化会失败---即序列化具有传递性3 当一个对象的实例变量引用了其他对象,序列化这个对象的时候会自动把引用的对象也进行序列化(实现深度克隆)4 当某个字段被申明为 transient 后,默认的序列化机制会忽略这个字段5 被申明为 transient 的字段,如果需要序列化,可以添加两个私有方法:writeObject 和readObject或者实现Externalizable接口当然 还存在比实现 Seriablizable 更高效的序列化,这里不再展开叙述,可以自行查询
【借鉴】
转载地址:http://fnusn.baihongyu.com/